COCOLA: Coherence-Oriented Contrastive Learning of Musical Audio Representations
ICASSP 2025
Abstract
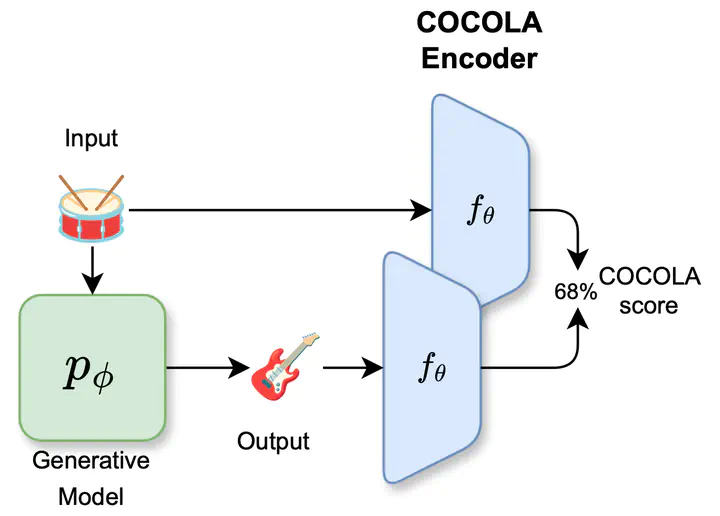
We present COCOLA (Coherence-Oriented Contrastive Learning for Audio), a contrastive learning method for musical audio representations that captures the harmonic and rhythmic coherence between samples. Our method operates at the level of the stems composing music tracks and can input features obtained via Harmonic-Percussive Separation (HPS). COCOLA allows the objective evaluation of generative models for music accompaniment generation, which are difficult to benchmark with established metrics. In this regard, we evaluate recent music accompaniment generation models, demonstrating the effectiveness of the proposed method. We release the model checkpoints trained on public datasets containing separate stems (MUSDB18-HQ, MoisesDB, Slakh2100, and CocoChorales).
Michele Mancusi
Senior Research Scientist, PhD
Senior Research Scientist at Sony, focused on advancing generative audio models through deep learning