Hello world! 👋
I’m Michele Mancusi, a Senior Research Scientist at Sony. My work focuses on deep learning for generative models in speech, audio, and music utilizing Large Language Models (LLMs) and diffusion models to push the boundaries of what’s possible in audio technology.
Before joining Sony, I gained valuable experience as an intern at Microsoft and Musixmatch. At Microsoft, I worked on deep learning for unsupervised speech separation, and at Musixmatch, I focused on deep learning for singing voice detection.
I earned my Ph.D. from Sapienza University of Rome under the supervision of Prof. Emanuele Rodolà as a member of the Gladia research group. My doctoral research centered on music generation, source separation, and Natural Language Processing (NLP), contributing to advancements in the field of generative AI.
- Deep Learning
- Signal Processing
- Generative AI
- Music Generation
- Source Separation
- NLP
- Speech Synthesis
-

PhD in Computer Science, 2024
Sapienza University of Rome
-

M.S. in Physics, 2019
Sapienza University of Rome
-
B.S. in Physics, 2016
Sapienza University of Rome
Work Experience
- Research on deep learning for generative models for speech and audio with LLM and diffusion models.
- Worked with Dr. Stefan Uhlich in the AI, Speech and Sound Group. Conducted research on deep learning for effects removal and timbre transfer with diffusion models.
- Worked with Dr. Sebastian Braun in the Audio and Acoustics Research Group. Conducted research on deep learning for unsupervised speech separation.
- Worked with Dr. Loreto Parisi in the AI Team. Conducted research on deep learning for singing voice detection.
Publications
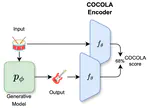
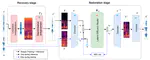

Achievements
- First-author paper selected among the top 1% submissions for an oral presentation at ICLR 2024
- Awarded €50,000 in AWS credit for the best generative AI research project
- Awarded €20,000 for the best machine translation research project
- Recognized as one of the top doctoral research projects and awarded research funding
Academic Experience
- Lectured at the Deep Learning and Applied AI MSc course and mentored students for their Master’s Thesis
- Delivered a guest lecture on the Latent Autoregressive Source Separation paper upon the invitation of Prof. Ronald Coifman