Abstract
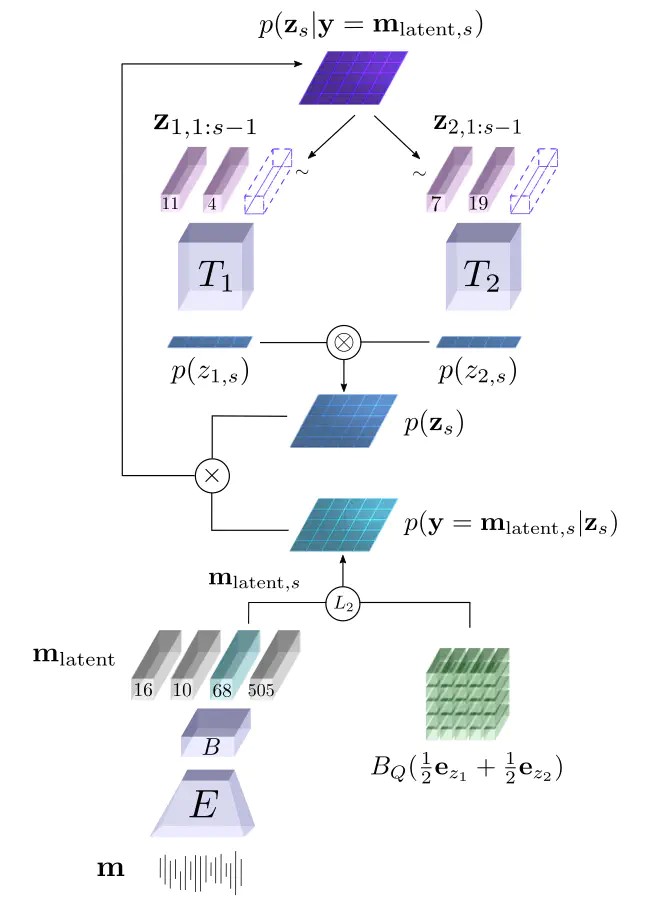
State of the art audio source separation models rely on supervised data-driven approaches, which can be expensive in terms of labeling resources. On the other hand, approaches for training these models without any direct supervision are typically high-demanding in terms of memory and time requirements, and remain impractical to be used at inference time. We aim to tackle these limitations by proposing a simple yet effective unsupervised separation algorithm, which operates directly on a latent representation of time-domain signals. Our algorithm relies on deep Bayesian priors in the form of pre-trained autoregressive networks to model the probability distributions of each source. We leverage the low cardinality of the discrete latent space, trained with a novel loss term imposing a precise arithmetic structure on it, to perform exact Bayesian inference without relying on an approximation strategy. We validate our approach on the Slakh dataset arXiv:1909.08494, demonstrating results in line with state of the art supervised approaches while requiring fewer resources with respect to other unsupervised methods.
Michele Mancusi
Senior Research Scientist, PhD
Senior Research Scientist at Sony, focused on advancing generative audio models through deep learning